Complicated Notions of Security
What are the common notions surrounding cryptography, and how can we demystify them? By Cryptographic Researcher, Charlie Grover, PhD
These days, most businesses are highly aware of the importance of securing their data. Even better, they also aware that security comes in two main formats: encryption, protecting their sensitive data from the eyes of malicious onlookers, and authentication, ensuring that the data was sent by the right person and hasn’t been tampered with in transit. However, cryptography is a big wide world, and sometimes encryption and authentication isn’t the end of the story. For example, let’s say you use the same identity to do all your online browsing, all adequately protected by authentication and encryption. What if someone was interested in tracking your online activity – sure, they can’t see what actual data you’re exchanging, or pretend to be you, but still, do you want anyone to know all your browsing habits? This sort of metadata can be quite valuable. If you’re always browsing at the same time each day, a potential robber could deduce what times your house might be empty. In the era of smart devices, this kind of privacy can be even more important, as plenty of your household items are constantly recording and transmitting data about your lifestyle!
Of course, everyone understands the core concept of privacy, but what does it mean on a cryptographic level? In this blog, I’ll walk through some “advanced” notions of cryptographic security that you might have heard of, and try to shed some light on the topic – what they mean, when you need them, and when you need to provide them as part of a product. For some uses, encryption and authentication are enough, and typically adding more complicated security measures means higher costs, but in other cases there are more modern and intricate security threats, so it is increasingly important to be aware of which properties you actually need!
Privacy
Privacy is undeniably a hot topic right now, especially with the advent of laws such as GDPR, but defining what exactly it is can be tricky. Generally, we understand privacy to be the right for individuals or other entities to maintain secrecy of what actions they are taking – what websites they visit, what happens in their home, who they are in contact with, and so on. However, this abstract definition doesn’t tell the full story. So what is privacy, and when should we think about providing it?
Cryptographically, the definition of user privacy depends on the use-case, but we think of it as hiding the identity of parties in a network. Going back to the web browsing example, if your connection protocol can hide the identity of the user (except to the server, which has to authenticate you somehow), then no one else can track your presence across the internet. This kind of privacy is actually provided by the TLS 1.3 protocol – before the client authenticates to a server, the connection is secured under a temporary layer of encryption. Thus, the client authentication, including the revealing of the user identity, is only visible to the server the client connected to. It is also possible to hide the identity of the server, although this is often of secondary importance – it’s not surprising that millions of people today connect to various internet browsers, for example; if you don’t know the identity of the users, it doesn’t really matter that you know that the endpoint, such as some Google or Amazon-owned server, was visited very often.
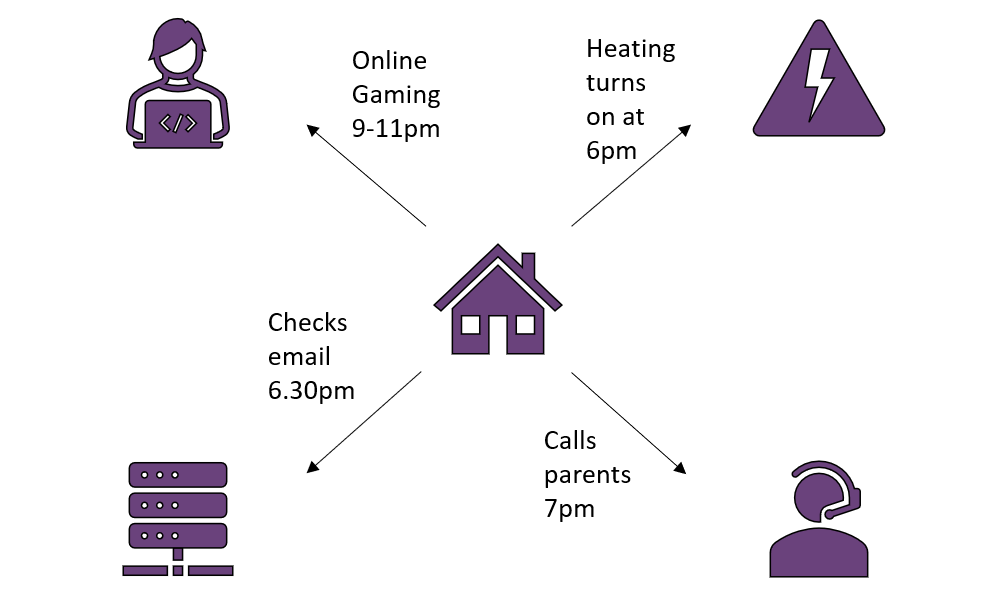
The TLS 1.3 idea of encrypting as early as possible is a reasonable rule of thumb for preserving privacy – any information transmitted before encryption is visible to everyone, and even if nothing explicitly sensitive is revealed in those messages they may leak some metadata: information about the connection performed. Depending on your use case, leaking metadata may be unimportant – there are probably simpler ways to figure out that I connect to my work email account every weekday than checking my network activity, for example – but other times it may be almost as damaging as leaking the information itself. The Cambridge Analytica scandal was mostly built upon high-volume harvesting of metadata to profile users, and has led to upheaval in social media giants’ policies on handling customer information. If the users identities had been obscured across the internet with suitable privacy preserving techniques, it is likely that it would not have been possible to build such complete profiles of the individuals.
So when do you need to worry about user privacy? A good starting point is to think about the following:
- Are you legally obliged to? GDPR and similar laws ensure a certain level of consumer privacy, and breaking the law is bad. Other countries have similar standards that must be followed when handling user data.
- Is the metadata important? This will depend strongly on the application, although as a rule-of-thumb people tend to vastly underestimate the value of metadata.
- Is it easy or expensive? Sadly, cryptography isn’t always cheap to implement, but lots of standardized protocols such as TLS have privacy either built-in or designed in a way that makes it easy enough to bolt-on.
In the case of privacy, I’d advise erring on the side of caution – metadata leaks are often surprisingly bad news, and attackers can do a lot with a little metadata. In the era of products that end up in people’s homes, the ethical risks and reputational damage of mishandled privacy will often outweigh the small savings made from not including it.
Foward Secrecy
Another slightly obscure notion of secrecy handled by a TLS 1.3 handshake is Forward Secrecy. To understand the definition of Forward Secrecy, we have to understand that there are two kinds of cryptographic keys used in practice: short-term keys, sometimes referred to as ephemeral, and long-term keys. Long term keys are typically public-private key pairs, used to receive communications or define the identity of a device or server – the owner is recognizable because of its known public key. Short-term keys are generated for a specific communication session (or sometimes sessions), so that if a user connects to the server, they can generate new, fresh, keys to encrypt their communication channel under. Short-term keys used in this context are also called session keys
Forward secrecy means that leaking a long term key, or a session key in a new session, does not compromise previously transmitted data. Although this sounds simple enough, forward secrecy requires a certain amount of forward (ha!) planning. Imagine a simple protocol, where a server has a public-private key pair for an encryption scheme, and to send data to the server you just encrypt it under the public key. Then, the server can decrypt the package using the private key. Easy enough to implement, but this setting provides no forward secrecy guarantees whatsoever! If the server’s key is eventually leaked, then all data that was ever sent to it can be decrypted. Instead, all data should be hidden under two keys – the long-term key and a series of updating short-term keys. This idea still applies if there’s no long term key, just a collection of short term keys: leaking the short term key for the current session should not provide information about short term keys used in previous ones! Of course, leaking the old short-term keys would leave old data vulnerable too, but the idea is that the short-term keys are deleted once you’re done with them, so that a compromise of the physical server where they were once stored does not leak the long since deleted keys.
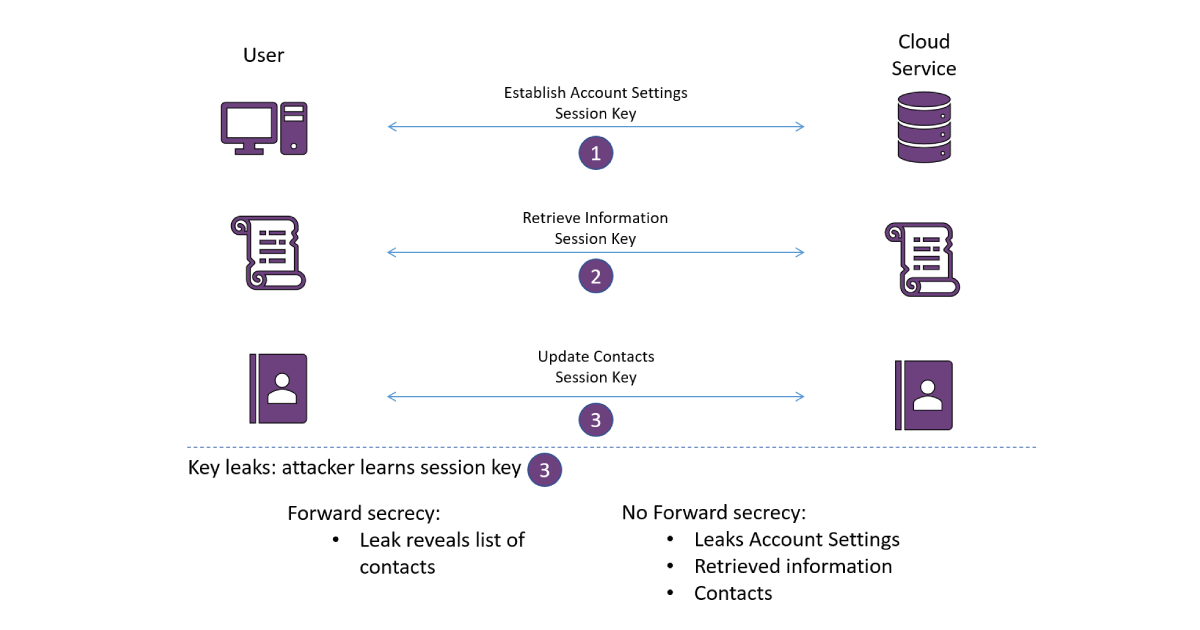
Although the concept of forward secrecy can be hard to understand, many well-known communication protocols such as TLS provide it as standard, as do various messaging apps such as Signal. It is relatively easy to provide in handshake-style protocols as long as ephemeral keys are generated for each session. Still, in some applications more complicated than web-browsing it can be harder to provide forward secrecy and its importance is not always obvious. Sometimes, long term keys will be stored in high-security physical locations and be subject to careful management, so that the chance of leaked keys in very low. Other times, the data encrypted is very time sensitive, for example in high frequency trading scenarios where completed trades are public, and in these cases the ability to decrypt past or old information is unimportant.
To summarize, the key considerations for providing forward secrecy are as follows:
- How time sensitive is your data? Data whose secrecy remains important for a long time should be protected extremely carefully, but if the data has a shelf life of a few hours, then forward secrecy can be low on the list of priorities.
- How likely are key leakages? Keys stored in well-maintained server centers are unlikely to be leaked, but keys stored on lightweight or edge devices deployed in unsecured locations are prime targets for physical attacks.
- How many keys are you using? If you’re repeatedly generating session keys, and the compromise of one of those keys somehow leaks all the data hidden under all of the keys, this is probably a bad set up – more keys means a higher chance that one of them is eventually misused or leaked. Instead, ensure forward secrecy so that compromising a key down the line does not affect old sessions.
End-To-End Encryption
Of all the topics covered in this blog, end-to-end encryption is the hardest to pin down a simple and concise real world definition for. Not because its hard to define intuitively or indeed cryptographically: in an academic sense, an encryption is end-to-end if it is encrypted by one party and can only be decrypted by the intended recipient – e.g. during transport it is always stored or exchanged in encrypted form, regardless of whether it is sent directly to the recipient or ferried on by some middle-man. However, in the real world, what exactly constitutes end-to-end encryption can be harder to pin down. After all, in some sense almost all encryptions are end-to-end! Someone encrypts a message at one end, and someone else decrypts it at another end. The tricky part is defining what you mean by an “end”, and what exactly lies between the endpoints. In the most basic cryptographic scenario where two parties send messages over an insecure channel, this is pretty straightforward, but in more intricate scenarios involving middle-men or multiple recipients, the waters can get a little muddied.
To illustrate the purpose of end-to-end encryption, lets imagine a simple, realistic, scenario with a single server acting as a central point of contact for many users. Users want to send messages to each other, but do not have a direct channel of communication except to the central server, which passes messages on to the intended recipient. An encryption is this setting is end-to-end if one user – let’s say User A – encrypts it, and it is not decrypted until received by the right user – User B. Achieving this sounds easy enough: User B generates a public-private key pair, transfers the public key to User A via the central server, who responds with an encryption of the intended message under this key. The server passes this encryption on to User B, who is able to decrypt using the corresponding private key. The encryption is end-to-end in the sense that although the message was relayed by the server, it has no means to inspect the contents – only User B is able to do this, because it is transmitted in encrypted form, only recoverable using a private key belonging to User B.
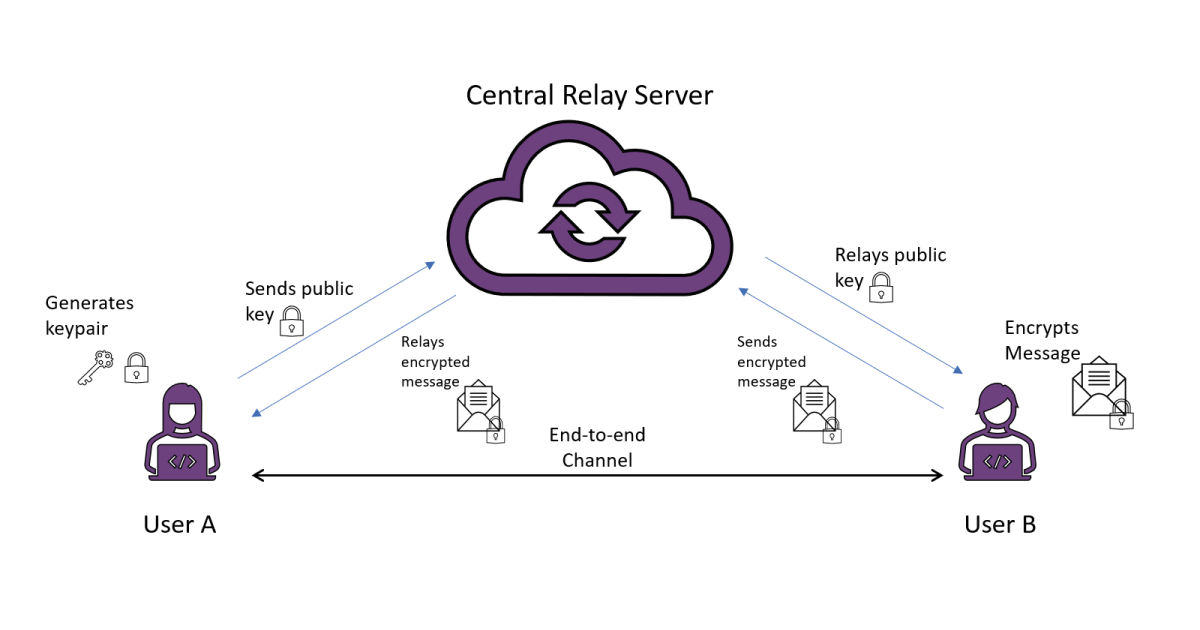
Unfortunately, this idealized scenario hides a reasonable amount of real world complications. Here, the goal for Users A and B is to exchange a message across the server without giving anyone else access to the contents. User’s A and B want to exchange a message through this server that they do not trust with the contents, but if they don’t trust the server to begin with then what is stopping the server tampering with some of the messages, such as sending User A a fake public key for User B, for which the server itself owns the private key? Then the message sent by User A can be easily intercepted at the server. It can even do this in a fashion that is very hard to detect – once its decrypted User A’s message, it can re-encrypt under User B’s public key and send it on to User B, who has no way of knowing that the server has seen the contents of the message; the user experiences of User A and B are the same in the honest scenario where the message is transferred securely. In fact, the server can be even more mischievous! If it decides it doesn’t want User B to receive the correct message, it can encrypt a fake message to User B under its public key. This “straightforward” end-to-end encryption isn’t starting to look very safe at all…
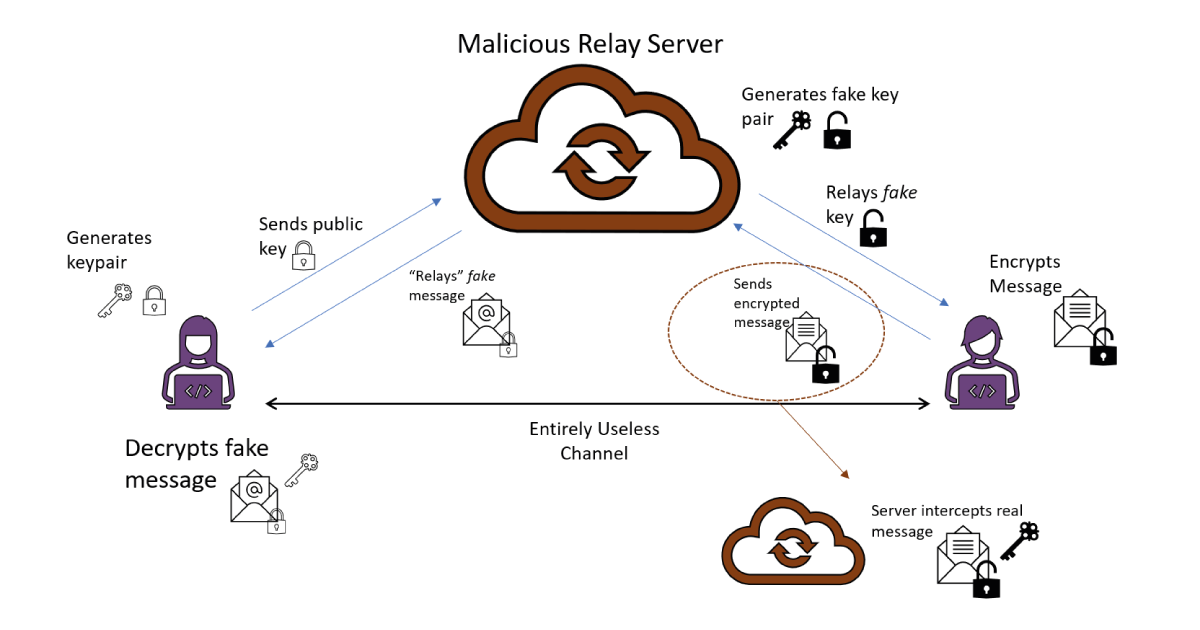
The vulnerabilities of the above setting assume that the server is willing to deviate from its intended purpose of just ferrying messages between users. Cryptographically, we can consider two kinds of adversarial model for the server: an honest-but-curious server, who will gather what information it can from the messages it sees but won’t break the rules, and an actively adversarial server, who is willing to deviate from its operating protocol to attack the users. In the honest-but-curious case, the end-to-end encryption works well, but we’ve just seen how an actively adversarial server can really ruin Users A and B’s experiences. Which kind of adversary you should consider the server to be depends heavily on the real world scenario – there are often serious legal or reputational risks to active adversarial behavior, especially when commercial contracts are involved, whereas being honest-but-curious is challenging to detect and is ultimately a relatively common human trait.
Of course, there are ways to mitigate the above threats, even against an actively adversarial server. For example, the encryptions can be made tamper-proof using standard authentication techniques, but these all bump into the same concern: how can Users A and B communicate through a central server without having previously exchanged any keys? This is a real problem when trying to implement end-to-end encryption: it is typically necessary for the two end-points to have some prior knowledge of each other, such as key material or a cryptographic identity, or maybe some form of hardware Root of Trust. In some scenarios, this is straightforward to achieve, but what if a new user, User X, joins the server? Their only method of communicating with old users is through the server, so they can’t exactly share keys with pre-existing users whilst hiding them from the server.
Although the single server with many users scenario is a simple one, and in practical applications end-to-end encryption may consider several middle-men, it illustrates many common issues in the area: any messages transmitted through a third party are subject to a variety of attack vectors and potential threats, and the less you trust the third party (or even parties!) the harder it is to come up with a secure system. However, if the centralized third parties are known to be trustworthy, either by reputation (like a Certificate Authority), tight legislative control, or they are owned by the same group as the users, then implementing end-to-end encryption can be quite easy. On the other hand, if there’s no harm in letting the server see the messages, you don’t really need the encryption to be end-to-end; each user has an encrypted channel with the server, who relays the plaintext messages between the two parties. This scenario comes up in cases where the server is trusted by all parties but the parties don’t necessarily trust each other or external parties: they still need to send encrypted messages between users, but aren’t concerned with protecting themselves from the server.
So what did we learn through this slightly meandering example, other than that end-to-end security is hard? There are many scenarios and use cases in which one might care about end-to-end security, so it is hard to give guidelines that will apply to all use cases, but some sensible considerations are:
- How much trust do you put in the parties between the two end points? If data has to go through one or more servers before reaching the recipient, do the parties care if the servers see their data or not? Are the servers likely to try to tamper with the data? Securing the channels between the parties and servers is easy, so data is most likely to be compromised at the server sites. The less you trust the server(s), the more careful you need to be about end-to-end encryption.
- How much information do the communicating parties have about each other? If they have some pre-shared material such as symmetric or public keys, achieving end-to-end encryption is quite easy. On the other hand, if they have no previous knowledge of each other, end-to-end encryption will be very hard to achieve without placing some trust in the server.
- Are the users sending information that either legally or contractually they are obliged to keep secret? If so, end-to-end encryption is a must as a due-diligence step to prevent intermediate parties intercepting the messages.
Overall, end-to-end security can be a slightly hard concept to get one’s head around. Perhaps it is easiest to think of it as an exercise in minimizing trust: don’t reveal anything you don’t have to middlemen, unless you are confident that they will not abuse any information or power they’re given.
Conclusion
As with all specialist industries, it is easy to get intimidated by the jargon used by security experts. Most people understand the need for encryption, and even authentication, but the more complicated concepts exist for a reason – in some scenarios, they are just as important as the simple encryption and authentication mechanisms they are built on top of. Hopefully, this blog has demystified a few of the common ones, and now it’s a little easier to decide whether or not you need to pay attention to them! Security doesn’t always come cheap, so understanding if and when you need to implement more intricate protocols is essential for building a product that is both secure and cost effective, and doesn’t have any hidden vulnerabilities!
Additional resources
Whitepaper
Enabling Cloud Connectivity in Resource-Constrained IoT Devices: A Wi-Fi Module and Low-End MCU Approach
This paper explores an affordable and efficient approach to embedded device cloud connectivity using a Wi-Fi module with a low-end microcontroller unit…
Read more
Whitepaper
Hardware Root of Trust: QDID PUF & Attopsemi OTP
This whitepaper presents a simplified, secure, and ready-to-use root-of-trust solution for embedded devices by integrating Attopsemi’s I-fuse technology…
Read more
Whitepaper
QuarkLink for Industrial PCs
This white paper introduces how Crypto Quantique’s QuarkLink SaaS device security platform is used with industrial PCs running Linux.
Read more