How to Separate your Cryptographic Keys
By Amit Deo, PhD, and Senior Cryptography Researcher at Crypto Quantique. We look at one of the most prominent principles in cryptographic design, the principle of key separation.
When designing cryptographic protocols and systems, many guiding principles ought to be respected. Often, these guiding principles are lessons learned from years of attacks and vulnerabilities against supposedly secure systems. Today we will look at one of the most prominent principles in cryptographic design – the principle of key separation. While the ideas behind key separation seem straightforward, we will see that it is not always trivial to spot cases of poorly implemented key separation. To show this, we will look at the example of the recent attacks on the MEGA cloud storage platform that leverage poor key separation to achieve a full breach of security.
What is key separation?
The key separation principle is remarkably simple – do not reuse secret key material in different contexts. For example, suppose you have a long string of bits being used as an encryption key. Then the key separation principle says that you should not reuse these bits as a signing key. This example is an obvious violation of the key separation principle as the two uses of the key are entirely different – an encryption key provides confidentiality whereas a signing key provides authentication.
Example: The TLS protocol implements good key separation. Take TLS 1.3 for example. A client and server engage in a TLS handshake, performing an elliptic curve ephemeral Diffie-Hellman key exchange (ECDHE) to agree on a collection of secret keys. During this handshake, some single-use keys are derived. For example, there is a single-use key that the server uses to encrypt its first handshake response and a distinct “key confirmation” key that provides a way for the client to confirm that the handshake has been completed successfully. Once the handshake has been completed, there is further key separation. Specifically, there is one key to authenticate and encrypt bulk application data from client to server, and an entirely separate key providing the same from server to client.
A warning: what does “different contexts” really mean? The principle of key separation is more subtle than this initial example. This is due to the vague meaning of “different contexts.” When attempting to implement key separation, it is important to not rely solely on the intuition above. Rather, one should understand why we do the key separation. As we will see, there are cases where it seems as though a single key is being used in a single context e.g., a single key is being used to encrypt multiple different keys stored on a server. However, better key separation would use one distinct key to encrypt each key stored on a server. This will be elaborated on in the MEGA case study, but more understanding of the vague meaning of “different contexts” can be discerned by answering the following question: why should we bother with key separation?
More importantly, why bother with key separation?
For many applications, it is difficult to design a system that provides the desired utility while resisting attacks. If a system is overly complex, it may even be hard to characterize all possible attack surfaces that a hacker may have access to. Even worse, an imperfect implementation of an otherwise secure system design may lead to unexpected vulnerabilities. Key separation helps mitigate the consequences of both design and implementation flaws.
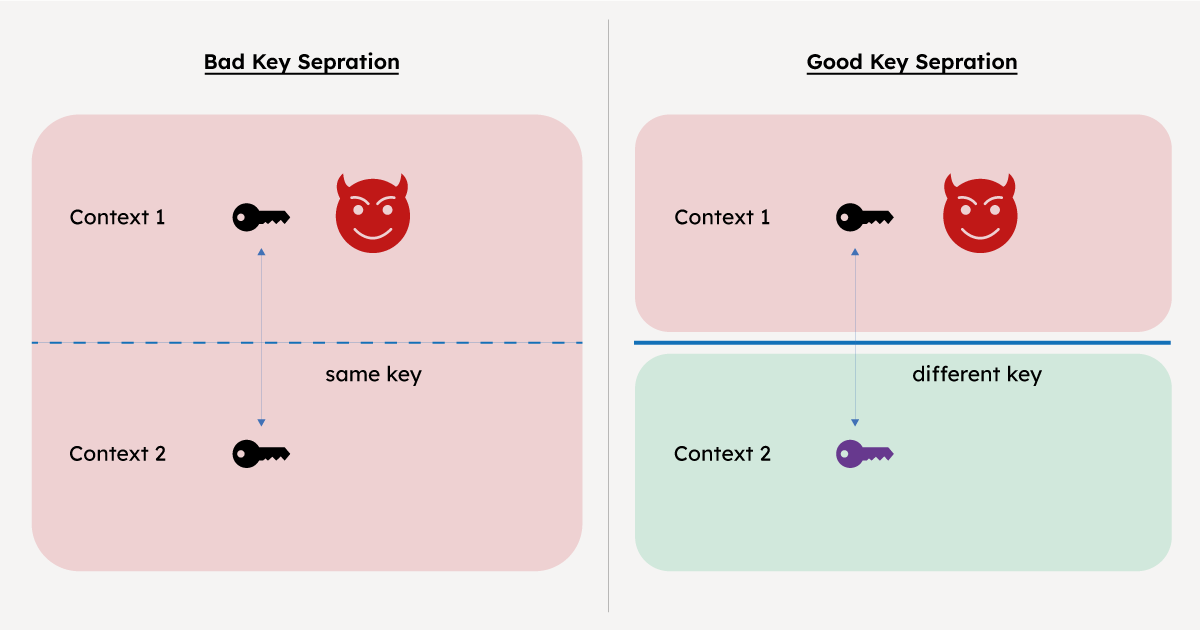
For example, suppose that you have a system that reuses a single secret key: once as a signing key for authentication and once as an encryption key for file storage. Then if an attacker somehow manages to subvert your authentication mechanism, it may be able to gain some sort of access to the signing key. At this point, this access could be used to decrypt your files. On the other hand, suppose the system was designed with good key separation. Then the vulnerability in the authentication mechanism cannot be used to leverage a full-scale decryption attack on stored files. Therefore, key separation isolates the effect of attacks on modular parts of a larger system. For a pictorial representation, see Figure 1.
How to do key separation
Ok, so we have seen what key separation is and why it is a clever idea. However, to use key separation, we require one key per context. If we have many contexts, then we will need to store many keys securely. This is especially problematic when there is a limited amount of storage or key material. For example, IoT devices that use physical unclonable functions to derive keys can create just a limited number of them. On the other hand, an IoT device that uses an RNG to derive keys can produce as many keys as it wants. However, such a device would have to store the keys, which may take up an unacceptable amount of memory.
Thankfully, there is a simple “best practice” solution to this issue – use a KDF (key derivation function). More specifically, it is often recommended to use HKDF which has a special parameter called the “info” parameter. Essentially, HKDF takes in an info parameter and some initial key material and outputs a new key. There is also a salt parameter and an output length parameter that dictates the length of the output key. The neat thing about HKDF is that the same initial key material can be used with different info strings to produce many cryptographically independent keys. If a key with one info parameter is compromised, then a key is created with the same initial key material, but different info parameter remains secure. It should be clear that HKDF provides a way of bypassing the lack of key material/storage problem that arises when trying to implement good key separation.
A recent example: Mega-awry
It may seem that the principle of key separation is simple and that applying it does not require much thought. As a result, one might think that key separation is not an issue in modern-day systems. However, as the recent example of the MEGA cloud storage platform shows, implementing good key separation is not always easy. In 2022, the researchers Backendal, Haller, and Paterson (mentioned from now on as [BHP]) discovered a series of attacks on the MEGA system. One attack on an individual component of the MEGA system is extended to a much more devastating attack thanks to poor key separation. We will only discuss their findings in terms of key separation, but their techniques and findings go much further than what is written here. To learn more visit MEGA: Malleable Encryption Goes Awry (mega-awry.io).
The MEGA key hierarchy
First, let’s see what keys are involved in the MEGA system. Each user account has several keys associated with it: a file-sharing key, a chat encryption key, a signing key, and some file encryption/integrity keys. To enforce key separation, each file/folder has its own freshly generated file encryption/integrity secret key. Furthermore, all the keys mentioned so far are independently generated and maintain good key separation. However, to keep these keys secret, they are stored in encrypted form on MEGA servers. The trouble is that all the keys are encrypted with the same key. This encryption key is called the master key and is derived from a user password. This is depicted in Figure 2. One may think that the master key is being used in a single context – to encrypt user keys. But we come back to the issue of the vague term “different contexts”. Without a deeper understanding of why we do key separation, things seem fine. However, if we understand why we do key separation, this system does not seem quite right because any sort of compromise of the master key can be used to decrypt all user keys. More to the point, a weakness in any of the mechanisms using the master key may have a huge effect on the security of all user keys.

Leveraging poor key separation as an attacker
Now one of the findings of [BHP] was that the lack of an integrity check on the sharing key ciphertext can be used to launch an attack that recovers the sharing key (which is one of the keys encrypted by the master secret). This attack does not recover the master key. However, the revealed value of the sharing key allows the attacker to cleverly decrypt ciphertexts encrypted with the master secret key. In other words, the reuse of the master key and lack of integrity checks on the sharing key ciphertext lead to an attack recovering all user secret keys.
The recommended countermeasures
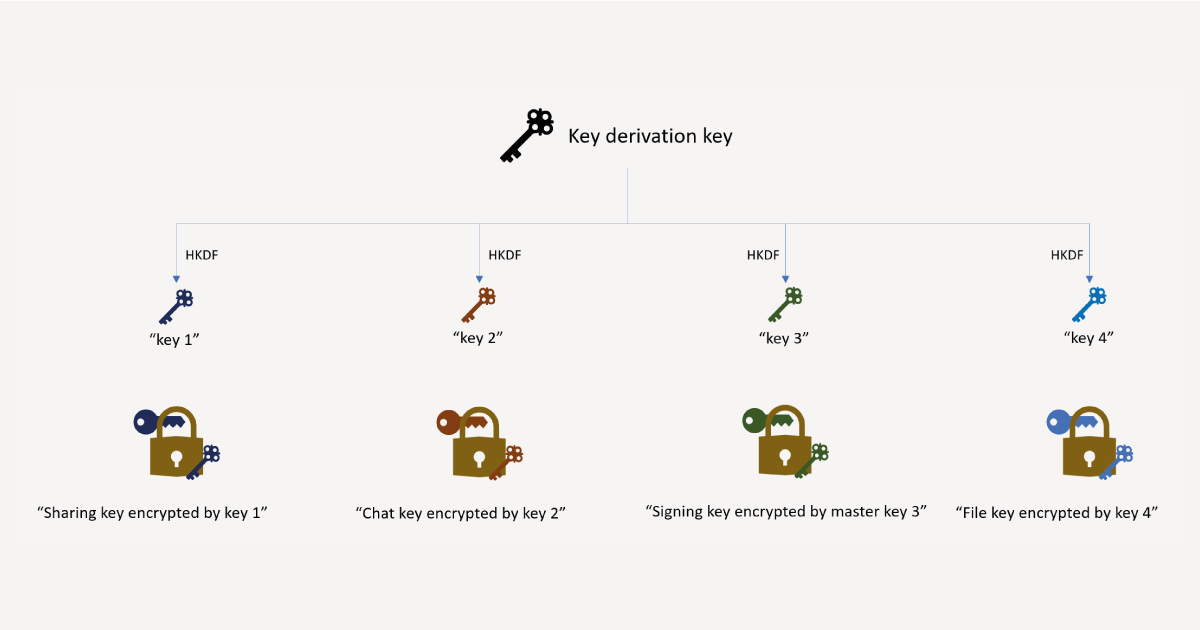
Within the list of suggested countermeasures is the recommendation to implement better key separation. In particular, the recommendation essentially removes the reuse of the master key. Instead, the master key is replaced by a key derivation key which is used to create multiple encryption keys – one to encrypt each separate key. The creation of these encryption keys is done by applying HKDF to the key derivation key with different info parameter strings. Note that there are other countermeasures addressing aspects of the attacks not discussed here, including improving padding formats, and adding integrity checks to ciphertexts. Once the key separation countermeasures are we end up with the picture in Figure 3.
A summary of key separation
The intuition behind the principle of key separation sounds simple – do not reuse keys in different contexts. However, as the case of MEGA shows, it is not always clear what “different contexts” are. To ensure that good key separation is being implemented, it is important to sceptically view a system in the worst-case scenario. Specifically, if one modular piece of a system is vulnerable to attack, does key reuse open the door for even worse security breaches? Or does the structure of keys isolate the effects of possible attacks? Answering questions like these allow for a much deeper understanding and reduce the chance of poor design due to overly simplified intuition on key separation.
Additional resources
Whitepaper
Enabling Cloud Connectivity in Resource-Constrained IoT Devices: A Wi-Fi Module and Low-End MCU Approach
This paper explores an affordable and efficient approach to embedded device cloud connectivity using a Wi-Fi module with a low-end microcontroller unit…
Read more
Whitepaper
Hardware Root of Trust: QDID PUF & Attopsemi OTP
This whitepaper presents a simplified, secure, and ready-to-use root-of-trust solution for embedded devices by integrating Attopsemi’s I-fuse technology…
Read more
Whitepaper
QuarkLink for Industrial PCs
This white paper introduces how Crypto Quantique’s QuarkLink SaaS device security platform is used with industrial PCs running Linux.
Read more